Java NIO: 非阻塞服务器,原文地址:http://tutorials.jenkov.com/java-nio/non-blocking-server.html
即使你已经理解了 Java NIO 中一些核心概念(比如选择器,管道,缓冲区等),但是设计一个非阻塞服务器仍然是非常困难的。相对于阻塞式 IO 来说,非阻塞式 IO 使用起来还是有些难点的。这篇非阻塞式服务器教程将讨论解决这些难点的主要方法。
关于如何设计一个非阻塞式服务器这个问题,我们能找到的有用的信息并不多。因此,本文中提到的方法只是基于我自己的工作和想法。如果你有其他更好的方法,请告诉我。你可以在本文下方的评论区回复我或者发邮件告知我(可以在 About 页面找到我的邮箱地址),也可以在 Twitter 上艾特我。
本文主要围绕着描述设计 Java NIO 服务器的方法。但是,我相信这些方法同样适用于拥有一些像 Java NIO 中选择器等结构的语言。据我所知,选择器这些结构是由底层操作系统提供的,所以学习本篇教程后你也会加深其他语言的理解。
Non-blocking Server-Github Repository
关于本文中讲解的原理实践代码,我已经把它放在了一个 Github 仓库里。下面是仓库地址:
https://github.com/jjenkov/java-nio-server
Non-blocking IO Pipelines
非阻塞的 IO 管道是连接其他模块的链条。这包括了非阻塞风格的读写操作。下面的插图展示了最简单的非阻塞式 IO 的管道: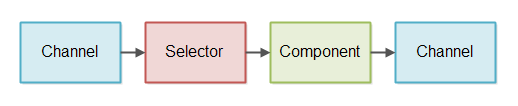
这图展示了一个模块使用选择器来监听管道中是否有数据可读。该模块从管道读出数据后经过处理再此输出到另一个管道中。
一个非阻塞式 IO 管道并不需要同时读写数据。一些管道仅仅读取数据,而另外一些管道仅仅是写数据。
上面的图仅仅展示了一个单一的模块。一个非阻塞式 IO 管道可能拥有超过一个处理数据的模块。非阻塞式 IO 管道的长度取决于该管道需要完成什么工作。
一个非阻塞式 IO 管道也可能同时从多个管道中读取数据。例如,从多个套接字管道中读取数据。
上图中流的控制是清晰简单的。模块通过选择器初始化了读数据的管道。这里并不是管道把数据推送到了选择器,虽然我们建议这么做。
Non-blocking vs. Blocking IO Pipelines
非阻塞式 IO 和阻塞式 IO 最大的不同之处在于怎么从管道(套接字连接或文件)中读取数据。
IO 管道通常从流(套接字连接或者文件)中读取数据,并把数据分割成特定的块。这就像是使用分词器将数据分成可解析的词。相应的,我们将流数据分割成较大的消息。我会调用一个模块将流数据分割成消息读取器可以读取的词。下图展示了消息读取器将流数据分割成消息:
阻塞式 IO 接口可以使用 InputStream 这样的接口从管道中读取数据,并且 InputStream 这样的接口会阻塞线程直到管道中有数据可读。这也就是实现了一个阻塞式消息读取器。
使用阻塞式 IO 接口大大简化了消息读取器的实现。一个阻塞式消息读取器并不需要处理流中没有数据可读或者仅仅从流中读取了部分消息抑或消息需要之后再做解析。
同样很简单的,一个阻塞式消息写入器(一个可以向流中写入消息的模块)也不需要担心只有部分消息被写入,抑或后续还有消息需要写入的情况。
Blocking IO Pipeline Drawbacks
一个阻塞式消息读取器是很容易实现的,但是不幸的是,它有一个明显的缺点,那就是必须有一个单独的线程来处理每一个需要分割成消息的流。这么做的原因是每个流的 IO 接口会阻塞线程直到可以读取到数据为止。这也就意味着一个线程阻塞在一个没有数据的流时,没法去读取其他流的数据。一个线程在从一个流中读取数据时,会一直阻塞直到该流中有数据可读。
如果这种 IO 管道应用于一个需要处理大并发连接的服务器端,服务器端将需要为每个到来的连接分配一个独立的线程。如果只有几百的并发量到没什么问题。但是,如果并发量高达百万,这种设计并没有良好的伸缩性。每个线程栈都会消耗 320K(32 bit JVM)或者 1024K(64 bit JVM)的内存。因此,1 000 000 个线程将会消耗 1 TB 的内存!并且在处理到来的消息之前服务器也会消耗一些内存(例如,为处理消息过程中使用的对象分配的内存)。
为了降低线程的数量,许多服务器使用线程池的来处理到来的消息。到来的连接会被放入一个队列中,然后线程会依次处理这些连接。下图展示了这种设计: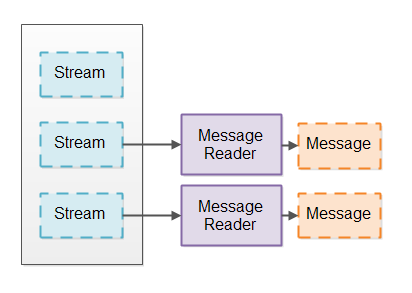
然而这种设计需要服务器端快速响应。如果处理每个连接需要花费很长时间,那么多个连接就会阻塞线程池中的所有线程。这也就意味着服务器会变得响应很慢甚至并不响应。
一些服务器通过一个可伸缩的线程池来解决这个问题。例如,如果线程池中的线程被用完,线程池会启用更多的线程来处理负载。但是,请记住,你可以使用的线程数还是有上限的。因此在百万级并发的情况下,这种方式也没有良好的伸缩性。
Basic Non-blocking IO Pipeline Design
非阻塞式 IO 管道可以使用一个线程来从多个消息流中读取消息。这要求流可以切换到非阻塞模式。当处于非阻塞模式下时,你从一个流中读取数据时,流可以返回 0 或者一些数组。如果流中没有数据可读,那么便返回 0。当流中有数据可读时,便会返回可读取的字节数。
为了避免每次都要检测流中是否有数据可读,我们使用 Java NIO 选择器。一个或多个选择器管道可以注册到一个选择器上。当你在调用一个选择器的 select() 或 selectNow() 方法时,它将返回处于有数据可读状态的管道。这种设计如下图: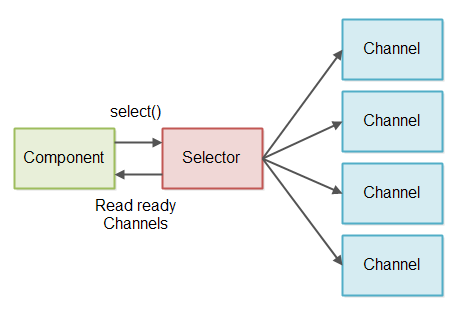
Reading Partial Messages
当我们从一个选择器管道中读取出一块数据时,我们并不知道这个数据块是否只是一个消息的一部分或者是超出了一个消息。一个数据块可能包含一部分消息(少于一个消息),一个完整的消息或者超过了一个消息,例如 1.5 个消息或者 2.5 个消息。就如下图所示的那样: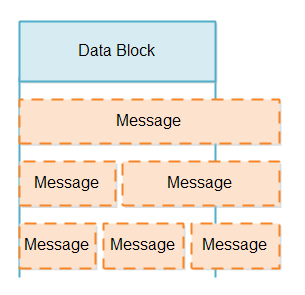
处理这种部分消息有两个难点:
- 持续检测一个数据块是否有一个完整的消息
- 在只有部分消息的情况下怎么做
检测完整消息要求消息读取器一直观察数据块中的数据是否包含一个完整的消息。如果数据块包含了一个或者多个完整的消息则可以将这个数据块发送到管道中去处理。观察消息完整性的进程需要一直重复进行,因此这个进程需要尽可能的快。
无论何时,一个数据块中有不完整的消息,则这个数据块需要被暂存直到消息剩余的部分也抵达了才可以进行处理。
检测消息的完整性和暂存不完整的消息是消息读取器的责任。为了避免不混合多个管道的消息,我们针对每个管道使用一个消息读取器。就像下面这样: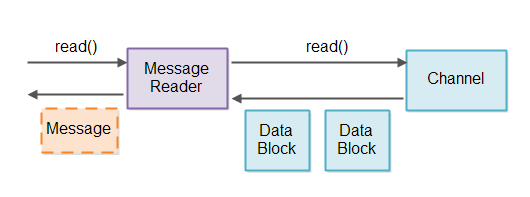
从管道中检索出数据时,与该管道关联的消息读取器会读取数据并将其分割为消息。然后,这些消息就可以被传递给其他需要处理它们的模块。
一个消息读取器是协议会在协议中指定。消息读取器需要直到消息的格式。如果服务器端的实现注重可重用性,那么它的消息读取器会来自可配置的消息读取器工厂。
Storing Partial Messages
现在我们已经知道了消息读取器需要暂存消息,然后我们还需要弄清楚暂存消息是怎么实现的。
我们需要考虑到两点:
- 我们想要复制的消息数据越小越好。因为复制的越多,性能越低。
- 我们想要一个完整的消息可以按序存储以便解析。
A Buffer Per Message Reader
很明显,我们需要使用某种缓冲区来暂存消息。最直接的实现就是在每一个消息读取器中使用一个缓冲区。然而,这个缓冲区该是多大呢?它必须足够大以便可以放下一个消息。因此,一个消息最大是 1 M,那么消息读取器内部的缓冲区就得至少是 1M。
当有百万个连接时,为每个连接分配 1M 的内存并不现实。1 000 000 x 1MB 仍然是 1 TB!并且,如果消息最大值是 16MB,或者 128 MB呢?
Resizable Buffers
另外一个选择就是在每一个消息读取器中使用一个大小可变的缓冲区。一个大小可变的缓冲区刚开始是很小的,如果消息比较大的情况下,则这个缓冲区会自动扩展。使用这种方式,每个连接没必要都使用 1MB 的缓冲区。每个连接仅仅需要消耗可以装载下个消息的大小的缓冲区。
实现一个大小可变的缓冲区有多种方法。它们各有优缺点,因此我将在下面依次讨论它们。
Resize by Copy
实现可变大小的缓冲的第一个方法就是起始使用一个小的缓冲区,例如 4KB。如果消息大于 4KB,那么再分配一个较大的缓冲区,例如 8KB,然后把 4KB 中的数据复制到大的缓冲区。
这种通过复制实现的大小可变缓冲区的有点在于可以保持每个消息都在一个单独的数组中。这是解析消息变得很容易。缺点就是如果消息过大的话导致大量数据被复制。
为了减少数据的复制次数,你可以分析消息的大小来寻找可以减少复制次数的最佳缓冲区大小。例如,你也许会发现大多数的消息都是小于 4KB 的,因为它们仅仅是很小的请求和响应。这也就意味着第一次缓冲区大小应该为 4KB。
然后你又发现因为有些请求包含了文件所以它的消息是大于 4KB的,但是确是小于 128KB。然后你就知道第二次缓冲区大小应该为 128KB。
最终你又发现有些消息是大于 128KB的,因此你并不能找到固定的数值。