Java NIO 缓冲区,原文地址:http://tutorials.jenkov.com/java-nio/buffers.html
Java NIO 缓冲区一般和 NIO 通道一起使用。正如你已经知道的,数据可以从通道读取出来写入缓冲区,也可以从缓冲区读取出来写入通道。
缓冲区是你可以从中读写数据的内存块。正是一个 NIO 缓冲区对象包含着这么个内存块,而缓冲区对象提供了一系列的方法可以让你操作这个内存块。
基本用法
使用缓冲区读写数据一般需要遵循以下四步:
- 写数据到缓冲区
- 调用
buffer.flip()方法 - 从缓冲区中读出数据
- 调用
buffer.clear()或者buffer.compact()方法
当你向缓冲区写入数据时,缓冲区对象会自动记录你写入了多少数据。当你想要从缓冲区中读取数据时,你需要调用 flip() 方法切换写模式到读模式。使用读模式后,你可以读取缓冲区中的所有数据。
一旦你读取完所有的数据,你需要清空缓冲区,为下一次写入数据做好准备。清空缓冲区的方式有两种:clear() 和 compact()。clear() 方法清空缓冲区所有内容,而 compact() 方法只会清空你已读的内容。所有未读的数据将会被放在缓冲区开始的地方,之后再写入的数据将会放在未读数据的后面。
以下是缓冲区的使用例子,里面综合运用了上文提到的几种操作:
## 缓冲区容量,位置和限制
一个缓冲区代表着一块内存区域,你可以向里面写入数据,也可以从其中读出数据。而一个 NIO 缓冲区对象就就表示这么一块内存区域,而缓冲区对象提供了一系列可以方便操作这块内存区域的方法。
为了理解缓冲区具体是怎么实现的,我们需要了解缓冲区的三个属性:
- 容量
- 位置
- 限制
“位置”和“限制”的含义在读模式和写模式下有所不同。而“容量”的含义在两种模式下是相同的。
下面的插图展示了读模式和写模式下容量、位置和限制的含义。如果你没看懂,那就继续看下面的解释。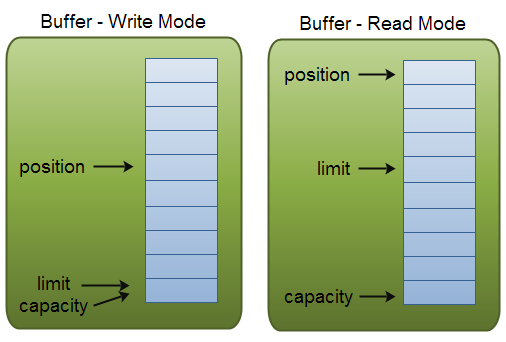
容量
作为一块内存区域,一个缓冲区对象有一个确定且固定的大小,我们称这个“大小”为“容量”。你向缓冲区写入数据时,并不能超过其容量的限制。一旦缓冲区写满了,在继续写入之前你需要清空它(读出其中的数据,或者清空它)。
位置
当你向缓冲区写入数据时,你是在一个该缓冲区代表的内存区域的一个特定位置写入数据的。刚开始这个特定位置是 0。当你写入一个单元(这个单元可以是一个字节,一个长整数类型,这取决于缓冲区对象实现的具体类型)的数据后,这个特定的位置会移向下一个单元。位置最大值就是容量减一。
当你从缓冲区读数据时,你也时从一个给定的位置开始读取的。当你调用 flip() 方法从写模式切换到读模式后,位置会被重置为 0。随着你读取数据,这个特定的位置记录也会相应的后移。
限制
在写模式下,限制就是指你最多可以写多少数据到缓冲区。因此,写模式下,限制就等于容量。
当你切换到读模式后,限制就是指你可以从缓冲区读出多少数据。因此,当把一个缓冲区切换到读模式后,限制就是指读模式下的位置记录。换句话说,你最多可以读出你所写入的数据。
缓冲区类型
Java NIO 中缓冲区的所有类型如下:
- 字节缓冲区
- 字符缓冲区
- 短整型缓冲区
- 整型缓冲区
- 长整型缓冲区
- 单精度缓冲区
- 双精度缓冲区
- 字节映射缓冲区
正如你看到的,这些缓冲区类型代表着不同的数据类型。
字节映射缓冲区有点特殊,我们稍后再单独讲解它。
分配一个缓冲区
为了得到一个缓冲区对象,首先你得分配它。每一个缓冲区类型都有一个 allocate() 方法用来非配缓冲区对象。下面是分配一个容量为 48 字节的字节缓冲区的例子:
然后是分配一个容量为 1024 个字符的字符缓冲区的例子:
向缓冲区写入数据
你可以通过两种方式向缓冲区写入数据:
- 从一个通道中读取数据写入缓冲区
- 通过缓冲区的
put()方法写数据到缓冲区
下面是从一个通道中读取数据写入缓冲区的例子:
然后是使用 put() 方法写数据到缓冲区的例子:
put() 方法有很多种版本,可以让你方便地以不同的方式向缓冲区写入数据。例如,在一个指定的位置写入数据或者将一个字节数组的数据写入缓冲区。想要了解详细信息,请自行查阅 API 文档。
flip()
flip() 方法将缓冲区从写模式切换到读模式。调用 flip() 方法将会设置位置为0,限制为位置所在的地方。
从缓冲区中读取数据
从缓冲区读取数据的方式有两种:
- 将缓冲区数据读到通道
- 通过调用
get()方法读出缓冲区数据
下面是把缓冲区数据读到通道的例子:
下面是调用 get() 方法读出缓冲区数据的例子:
get() 方法有许多不同的版本,可以让你方便地以不同的方式从缓冲区读出数据。例如,从一个指定的位置读取数据或者从缓冲区读取出一个字节数据的数据。想要了解 get() 方法的具体信息,请自行查阅 API 文档。
rewind()
方法 rewind() 设置位置为 0,这样你就可以开始从头读取缓冲区的数据了。限制含义仍然不变,还是表示你可以从缓冲区读出多少数据。
clear() 和 compact()
一旦你读完了缓冲区的数据,你需要将缓冲区重置以便下次数据的写入。你可以通过调用 clear() 或 compact() 方法来重置缓冲区。
当你调用了 clear() 方法之后,position 将被置为 0,而 limit 将被置为和 capacity 相同。也就是说,缓冲区被清空了。但是缓冲区里原有的数据并没有被清除,这只是可以让你可以从头写入数据而已。
当你不再读取缓冲区的数据时,调用了 clear() 之后,缓冲区将“忘记”自己保存的数据。这也就是说你不能再知道哪些数据读取过,哪些数据没有读取过。
如果缓冲区中还有尚未读取的数据,而你并不想丢弃这些数据。而此时你又需要写一些数据到缓冲区,那么该怎么办呢?没错,就是调用 compact() 方法。compact() 会将尚未读取的数据放在缓冲区的头部。然后把 position 指向未读取数据的后面,limit 属性设置为 capacity。现在你可以向缓冲区写入新的数据了,并且也不会覆盖之前尚未读取的数据。
mark() 和 reset()
你可以通过调用 Buffer.mark() 来标记当前的 position。然后你可以调用 Buffer.reset() 方法来将 position 重置为之前标记的值。下面是一个小例子:
equals() 和 compareTo()
比较两个缓冲区的话可以调用 equals() 和 compareTo() 方法。
equals()
如果两个缓冲区相等的话:
- 两个缓冲区是相同的类型
- 两个缓冲区剩余的空间是相等的(这里所谓的剩余空间是指
position到limit之间的空间) - 两个缓冲区剩余的空间的每个单元的值都是相等的
这个地方有点难于理解,其实看下该方法的源码之后就会瞬间明白了:equals() 方法比较的就是两个缓冲区尚未读取的数据是否相同的,从这一点上来看,已经读取的数据在逻辑上已经不再是缓冲区的数据了。
compareTo()
compareTo() 方法比较两个缓冲区剩余的数据(即尚未读取的数据),通常用来排序。我们说一个缓冲区“小于”另外一个缓冲区通常满足如下条件:
- 第一个缓冲区中的第一个不等于第二个缓冲区相应位置的单元,前者小于后者
- 第一个缓冲区拥有的数据在第二个缓冲区相应位置也有同样的数据,但是第二个缓冲区的长度大于第一个缓冲区的长度
如上个方法的解释,看这解释还不如直接去看下源码。